The way we think creates a picture of the world we are living in, and television has a significant impact on our personas. Imagine twins who were taken to different families and raised by different parents. Even though they have the same DNA, they will have different opinions on politics, culture, and economics.

We teamed up with developers from ISD GmbH and advertisement agency Voskhot to recreate a similar experiment and show the difference between propaganda and independent news leveraging Artificial Intelligence capabilities.

For this project, we built two neural networks and trained them with different datasets. The first network “watched” the governmental channel Russia-1 during a six month period, while the second network was trained with programs from the independent television channel Dozhd (TV Rain), broadcasted during the same period. To find out how those networks answer the same questions, we integrated both neural networks into a Telegram-powered chatbot. We made it available to the public via API on the AI VERSUS website.


After six months of training, chatbots were able to answer users’ questions based on the vocabulary from programs watched. Website visitors can vote for answers received and share answers on social networks. As a result, Rain TV’s AI bot got 93% of users’ votes.
Project goals and requirements
We were hired by ISD GmbH to complete the Machine Learning part of the project. We needed to:
- Select the best possible Machine Learning model for neural networks
- Choose and integrate the speech to text tool
- Train neural networks with Russia1 channel and Rain channel programs
- Create the user interface to enable chatbots to answer user questions
Challenges we overcame
At the beginning of the project, we faced two main challenges.
Script-based chatbots do not meet our goals
The majority of existing conversational agents (chatbots) operate on a pre-made script to perform particular tasks, such as booking tickets or ordering delivery. The purpose of our project was more complex – to create a neural network that will maintain a dialogue with the user like a real person and answer meaningful phrases without a predefined script.
Our Solution
In the beginning, we tried to find a ready-trained neural network model but failed to find one. Thus, we focused on developing Artificial Intelligence from scratch by testing and combining different AI models. The core of the project is the Trained Neural Network, the main component of the system, accomplished with an algorithm that can identify and build relationships between words and topics from the database.
The video format is unsuitable for neural network training
TV programs are broadcasted in video format. However, we could train neural networks using only text documents. Also, TV programs include different participants who support different ideas, so the neural network should understand the programming context.
Our Solutions
We decided to concentrate on such topics as politics, social issues, and culture. Then, we selected video programs on relevant topics and applied Google’s Speech-to-Text tool integrated into our system. The tool helped the network to identify the program’s language and a number of speakers, break down videos into abstracts, and record text to the project’s database. We knew that such an approach may result in some mistakes during text recognition, but it was the best possible option for us.
How we did it
Step 1. Choosing the training model
At the beginning of the project, we used a Question Answering Model (Q&A), which can answer questions. We tried this model on a small number of test datasets and received quite satisfying results for questions on specific topics. This model gathered answers from a limited amount of information from the database. However, to provide users with a real experience of communication with Artificial Intelligence, we needed to increase the amount of information in the database considerably. Unfortunately, the system was not capable of handling vast amounts of data due to the system’s limited memory. During the second development stage, we tried to overcome the system’s memory limitations, which ended without results.
Step 2. Leveraging ODQA model
During the second phase of our experiment, we leveraged the open-domain question answering (ODQA) model powered by Deep Pavlov. DeepPavlov is an open-source conversational AI library built on TensorFlow and Keras. The ODQA model was trained to find answers in a vast database, like Wikipedia. A model with basic settings performed poorly. However, we liked the Word Embeddings technology behind the ODQA model. World Embedding technology allows “embed” words in the text to receive their numerical representation, and conducts mathematical operations. Then, by applying the reverse embedding, we accept a meaningful phrase.
Thus, we decided to modify this model slightly and use it in our project.
Step 3. Integrating a context identification technology
World Embedding technology allows our system to not only find similar words, sentences, abstracts, and contexts. The context is a small part of a TV program on a particular topic with knowledge AI uses during a dialogue with a real user.
At this stage, we faced the challenge of how to decide which context suits the best. To solve this, we decided to use rankers. After testing several options, we decided to leverage TFIDF, short for term frequency-inverse document frequency. This numerical statistic reflects how important a word is to a document in a collection or corpus.
The higher the rate, the higher probability our system will answer with a meaningful phrase.
To make AI answer meaningful phrases, we needed to select the context with higher frequency and apply it to our first Q&A.
Step 4. Filtering out irrelevant questions
Unfortunately, our system wasn’t perfect on the first try and failed due to irrelevant questions,a lack of knowledge on some topics in the database, and system errors. At this stage, we needed to improve the system’s ability to define the content and make answers even more meaningful. Thus, we decided to teach the network to identify user questions better and correlate them with topics, which is quite a simple task for a Machine Learning algorithm. Its success depended on the quality of the education. Thus, we decided to release the existing system for free alfa testing on the Telegram platform to find out what questions are more critical for Russian citizens. During such an open trial, users asked questions, and the system tried to define the topic. The user could agree on the selected text or note that items belong to other issues. In this way, we successfully managed to filter out irrelevant questions that did not belong to our main topics (politics, economics, and life in the country).
Step 5. Getting the chatbot up and running
At this stage, we excluded irrelevant topics from both neural networks, developed an API to integrate the project into the website, added social sharing buttons so users could share answers received in Twitter, Facebook, and Vkontakte social networks, and officially released the project.
Since the project required a lot of space for operations, we used quite a powerful server with a large amount of RAM. However, we needed to save money on process resources, which impacted the chatbot answering time. On the other hand, such a delay in providing answers makes users feel that the chatbot thinks before answering something meaningful, like a real person.
Our tech stack
- Google Cloud Platform as a hosting environment
- Deep Pavlov, Doc2Vec/Word2Vec for neural network development and training
- Google Speech-to-Text API for converting TV programs into text documents
- Custom API for database management
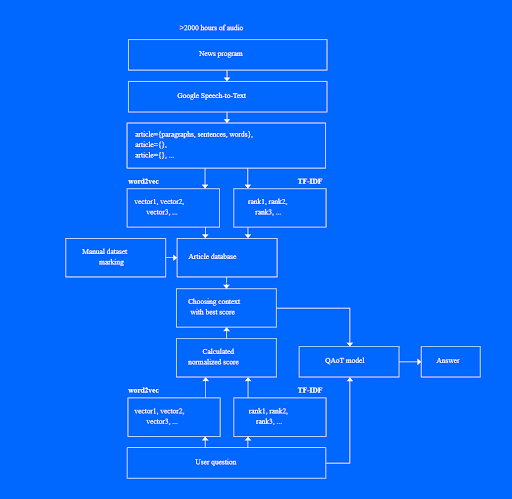
[AI Verses architecture view]
The APP Solutions Team Composition
- 1 Project Manager
- 2 Software Developers
- 1 QA Engineer
Results
We developed a comprehensive neural network that could be applied to almost any dataset. Once the project went life, it became viral, and around 193 428 visitors from 16 countries shared over 2 million of AI VERSUS’s answers on their social network profiles.
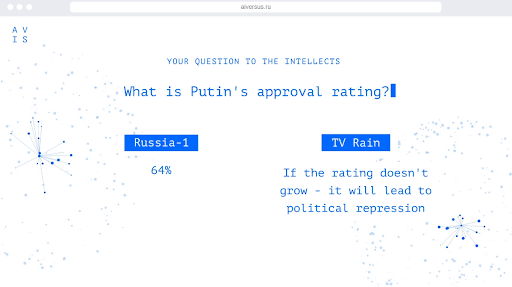
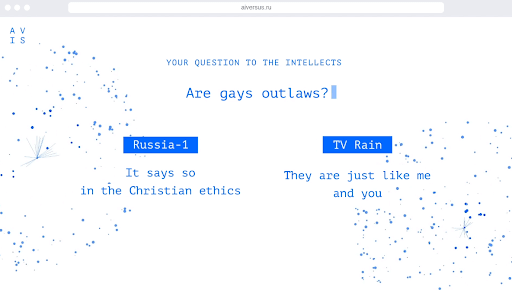

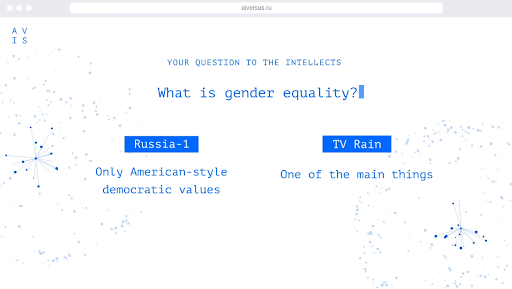
In this way, we, ISD GmbH, and Voskhod advertising agency, showed the real difference between propaganda and independent news. We hope that users, who communicate with AI VERSUS, have become more selective in the context they consume after seeing the difference in the answers of our neural networks.
We are also proud that the AI VERSUS chatbot project got third place at the Cannes Lions International Festival of Creativity on nomination Creative Data: Data Storytelling.
Get articles to your email once a month
Subscribe for updates