Today, there is so much information in the world that no human brain can process it. Just imagine, when surfing your favorite social network, you see, not relevant content from friends and interest groups in the feed, but in general, everything that anyone has ever added there. In a word, chaos and confusion! Few people would like this.
To avoid this, companies working with big data use various methods to analyze the video/audio and text content they have so that every consumer of goods or services remains satisfied and active on the site for as long as possible.

These methods include predictive analytics and data mining. They are often confused, considering that they are about the same thing. However, there is a difference, although it can’t be denied that the goal is the same – to lure as many consumers as possible under your commercial umbrella. One comes out of the other.
To explain the difference between data mining and predictive analytics, let’s first talk about each method.
WHAT IS ARTIFICIAL INTELLIGENCE IN HEALTHCARE?
What is Data Mining?
Data Mining is the process of simplifying and generalizing a colossal amount of data in a humanly-understandable way using machine learning technologies. During this process, various clusters of information are discovered, analyzed, sorted, and classified.
Thus, patterns are revealed based on which it is possible to draw certain conclusions and decide what to do next with the results obtained.
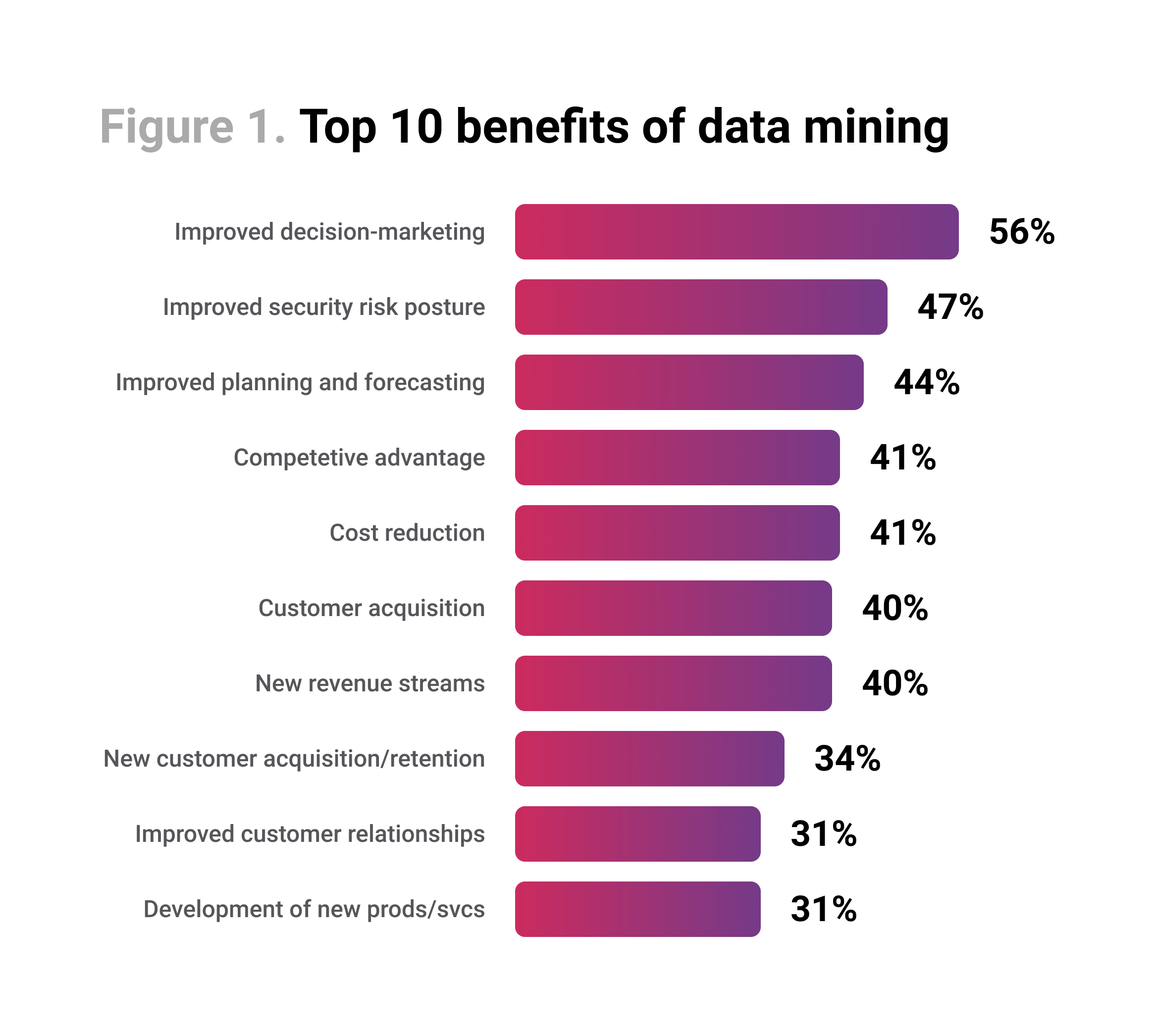
Depending on the subtlety of the customization, you can get hyper-precise results that will work for almost every client in a personalized way. According to a Microstrategy report, 92% of respondents plan to roll out advanced analytics capabilities in their organizations.
Data mining is also used in risk management, cybersecurity, and software optimization in addition to forecasting the demand for goods/services and predicting behavioral factors.
PREDICTIVE ANALYTICS VS. MACHINE LEARNING: WHAT IS THE DIFFERENCE
What is Predictive Analytics?
Predictive analytics is the process of extracting valuable data from an existing system and then identifying specific trends and tendencies, based on which you can plan further business steps. Then, based on previous experience, future results are modeled by using artificial intelligence and machine learning.
This does not mean a 100% likelihood of events. Still, a high proportion of predictions helps marketers and business analysts navigate which course to lead the company in the near or distant future.
What is the Difference between Data Mining and Predictive Analytics?
Data mining helps organizations build a background and understand the current situation. In addition, predictive analytics is taking on a more proactive role, allowing users to anticipate results and develop preemptive strategies for a wide range of future scenarios while avoiding crises.
Simply put, these are interconnected high-tech processes. Without data mining, predictive analytics could not have appeared in principle since there would be no place to get information for further predictions. And without predictive analytics, data mining would not make much sense either, since the mere presence of structured information, without a further action plan, is not a very useful tool. Data mining illustrates today’s picture, while predictive analytics tells you what to do with it tomorrow.
Thus, data mining turns out to be a stepping stone for predictive analytics. Apart from this, data mining is passive, while predictive analytics is active and can offer a clear picture.
HEALTHCARE CYBERSECURITY: HOW TO PROTECT PATIENT DATA
What solutions can we offer?
RPA IN HEALTHCARE: A COMPREHENSIVE OVERVIEW, BENEFITS, AND USE CASES
How Data Mining Works
Imagine that you have gathered three friends and decided which pizza to buy – vegetarian, meat, or fish? You just poll everyone and conclude what exactly needs to be ordered in your favorite pizzeria. But what if, for example, you have three million friends and several hundred varieties of pizza from several dozen establishments? It’s not so easy to deal with an order, is it? Nevertheless, it is what data mining specialists do.

KEEP A PULSE ON EPIC APP ORCHARD AND HOW IT BENEFITS THE HEALTH SYSTEMS
According to this principle, when you go to an online store to buy earrings, you will immediately be offered a bracelet, pendant, and rings to match. And to the swimsuit – a straw hat, sunglasses, and sandals.
It is precisely the ideally structured array of specific information that make it possible to identify a suspicious declaration of income among millions of others of the same kind.
Data mining is conventionally divided into three stages:
- Exploration, in which the data is sorted into essential and non-essential (cleaning, data transformation, selection of subsets)
- A model building or hidden pattern identification, the same datasets are applied to different models, allowing better choices. It is called competitive pricing of models
- Deployment – the selected data model is used to predict the results
Data mining is handled by highly qualified mathematicians and engineers as well as AI/ML experts.
HOW TO CREATE A MEDICAL APP: THE ULTIMATE GUIDE
How Predictive Analytics Works
According to a report by Zion Market Research, the global predictive analytics market was valued at approximately $3.49 billion in 2016 and is expected to reach approximately $10.95 billion by 2022, with a CAGR between 2016 and 2022 at about 21%.
Predictive analytics works with behavioral factors, making it possible to predict customer behavior in the future – how many will come, how many will go, how to change the product, and what promotions to offer to prevent consumer churn.

You can make predictions based on one person’s behavior or a group united by a specific criterion (gender, age, place of residence, etc.) Predictive analytics uses not only statistics, but ML, teaching itself.
Business analysts interpret forecasts from inferred patterns. If you don’t predict how your regular and hypothetical customers will behave, you will lose the battle with your competitors.
WHAT IS EHR (ELECTRONIC HEALTH RECORD), AND HOW DOES IT WORK?
Data Mining and Predictive Analytics in Healthcare
The healthcare system was one of the first to adopt AI technologies, including data mining and predictive analytics. It includes detecting fraud, managing customer relationships, and measuring the effectiveness of specific treatments. And, of course, there is such a massive layer of developments as predictive medicine based on predictive analytics.
Step-By-Step Guide On Mobile App Hipaa Compliance
Using the example of the latter, we will explain how it works. Let’s say you have a cancer patient like thousands of other patients in your hospital. Based on their treatment, you decide which regimen to choose for this particular patient, taking into account all of the characteristics. The more patients you add to the database, the more relevant solution will be given by the self-learning application for future patients.
Video Streaming App Proof of Concept
Another example: you can adjust the number of medical personnel in a hospital depending on the reasons for the visit. If most of the patients who come to you are kids, it’s time to expand the pediatric ward. AI will help the HR department see an impending problem before it becomes urgent. Also, such a system can predict peak loads in hours/days/months of hospital operation, which will make it possible to intelligently plan the shifts of doctors and nurses.

Clustering patients into groups will help assign a patient to a risk group for a particular disease before getting sick. For example, those prone to diabetes or disseminated sclerosis need to stick to diets so as not to worsen their health. If the patient prepares in advance, the course of the disease will be far less intense and more effectively treated.
But data analysis tools can be helpful not only for doctors. So, a special application can remind the patient that it is time to replenish the supply of prescription drugs, and if necessary, automatically pay for them at the nearest pharmacy and order home delivery.
MICROSOFT CLOUD FOR HEALTHCARE: HOW MS CLOUD SOLUTIONS ARE BENEFITING HEALTHCARE ORGANIZATIONS
Outcomes
According to spending data reported by the Centers for Medicare and Medicaid Services, the United States’ national healthcare expenditure reached $ 3.5 trillion in 2017. Applying a 12-17% savings to that number, the estimated cost reduction from system-wide data analytics efforts could earn between $ 420 billion and $ 595 billion.
It would be a crime to ignore such a lucrative market, where supply will not soon outstrip demand. Try trading with The APP Solutions now. Our company has excellent experience in developing health apps.