How to Create a Medical App in 2022: The Ultimate Guide
- What is a Medical App?
- What is the Difference Between a Health App and a Medical App?
- Types of mHealth apps
- Is Mobile App Development Profitable?
- Benefits of mHealth apps for business owners
- Healthcare Mobile App Development vs. Covid
- How to Build an Effective Medical Mobile App
- Healthcare mobile app development
- What tasks should healthcare mobile apps perform?
- Trends in mobile medical software development
- The APP Solutions and mobile app development services
- Outcomes
Healthcare mobile app development is a complex and demanding job that requires maximum concentration and attention to detail. The cost of a mistake in such an application can be money, health, or even a person’s life. Hence, before taking on the development of such a project you need to consider many nuances and, in no case, release a faster, “raw” product. Therefore, we will try to tell you about the most important aspects and features of healthcare mobile app development.
AGILE HEALTHCARE: HOW TO IMPLEMENT THE APPROACH
Mobile health is growing at a rapid pace these days. The demand for mHealth apps is driven by the growing prevalence of chronic diseases such as diabetes, cardiovascular disease, and obesity, as well as the increasing diffusion of digital health technologies. Among others, the monitoring services segment accounted for the largest share in 2019. Nonetheless, diagnostic services are projected to show the highest CAGR.
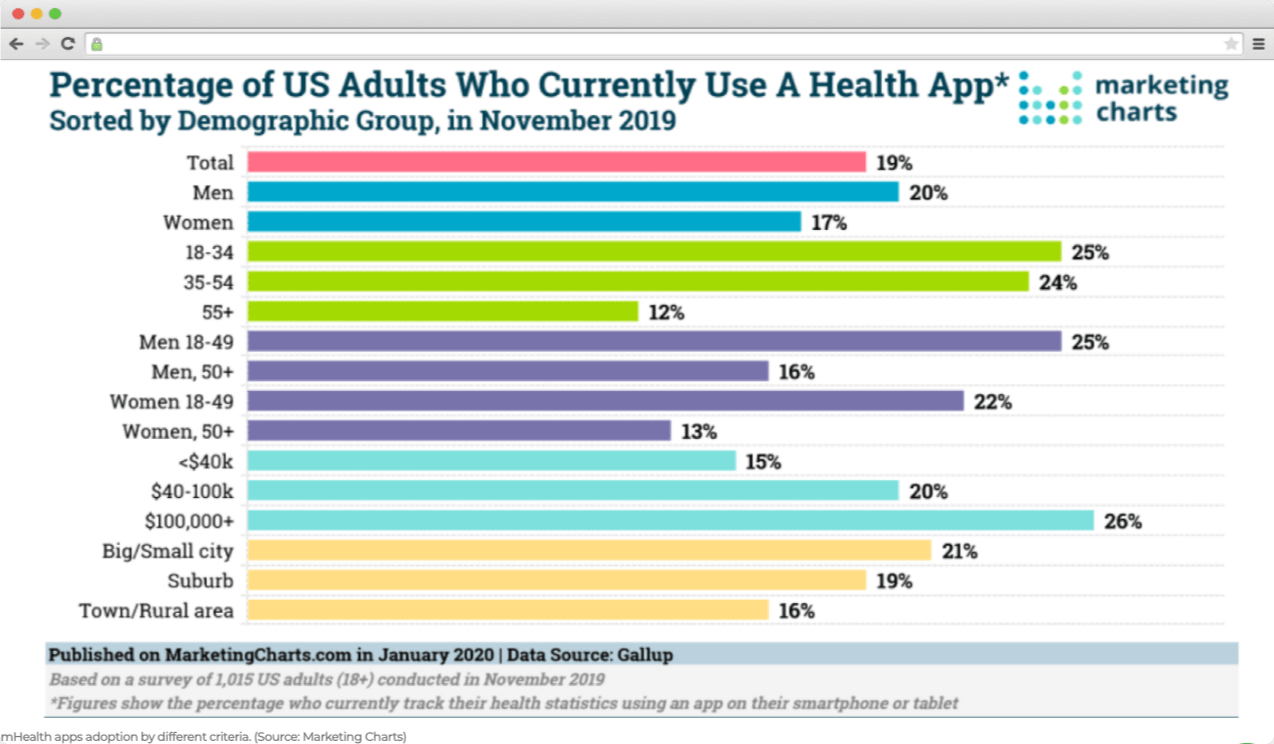
Covid 19 also contributed a lot to the spread of mobile healthcare apps. However, in 2017, about 64% of the U.S. adult population regularly used the app to measure health indicators. Still, there are some doubts about the confidentiality of personal information and data systems security. But this does not mean that such a suspicious audience cannot become a target – this will be another challenge for healthcare app developers in the cybersecurity field.
The healthcare app market is still far from being oversaturated due to its changes in recent years. Until a few years ago, the list consisted mainly of lifestyle and fitness apps. Now it is starting to include more and more apps focused on specific tasks. For example, working as a complementary medical app clinic or helping people with certain types of diseases. In the mobile health market, analysts have identified several main segments of applications designed for diagnostics, monitoring, prevention, treatment, and medical simulations.
Want To Build a Healthcare Mobile App?
What is a Medical App?
So, what kind of applications can be called medical or those related (albeit indirectly) to your health?
First of all, these are applications that help users effectively manage their physical/psychological illnesses and fitness achievements, as well as keep records of hospital visits and insurance payments.
HOW TO MAKE EHR/EMR EPIC INTEGRATION WITH YOUR HEALTH APP
Doctors, in turn, have their own goals when using mHealth apps. The Healthcare Information and Management Systems Society names the tools most commonly used by doctors:
- Collect bedside data
- Monitor data from remote devices
- Transmit data and coordinate care continuity
- Conduct telemedicine visits
- Communicate with patients
- Integrate data into EMR
Calmerry Online Therapy Platform
A White Label Telemedicine Platform
BuenoPR – 360° Approach to Health
As a result, Health IT Outcomes reports on a variety of usage trends by the physician and healthcare community:
- 93% of doctors believe mHealth apps can improve patient health
- 74% of the hospitals using mobile app devices to collect patient data are more efficient than those that don’t
- 42% of patients say they prefer digitally scheduling an appointment over calling their provider
With the reality of Covid 19, doctor visits quickly moved online. Furthermore, the clinicians themselves claim that 75% of calls do not really require the patient’s personal presence in the office, meaning most medical situations can be handled using telemedicine. This immediately gives tangible relief for ambulances.
CHOOSING TELEMEDICINE SOFTWARE DURING COVID-19: A COMPLETE GUIDE

What is the Difference Between a Health App and a Medical App?
The difference between a health app and medical app is that health apps are designed to provide health-related services for all types of smartphones and communication devices, whereas medical applications are software on mobile gadgets that users can apply to regulated medical devices.

Types of mHealth apps
For patients:
- Fitness and wellness apps
- Mental health apps (including meditation)
- Self-diagnosing
- IoT
- Applications for caring for the elderly and sick people
- Patient well-being diaries, vital sign monitoring (blood pressure, pulse, glucose, and cholesterol levels…)
- Health management apps such as hydration monitoring, calorie calculator, diet tips, etc.
- Social networking, health forums, and portals
- Assistants for pregnant women
- Womens’ health
- Telemedicine/Doctor on-demand
- Appointment and recipe reminders
- Medication management/Mood trackers/Sleep monitoring
STEP-BY-STEP GUIDE ON MOBILE APP HIPAA COMPLIANCE
For doctors:
- Medical resource and education apps that contain information about drugs, medical articles, or lists of symptoms
- Remote diagnostics
- Remote monitoring
- Communication
- Appointment management
- Telemedicine
The classification is limited to these two groups, but there is also a third cluster. These are medical applications for institutions that are somehow related to the medical industry.
- Clinical assistance apps with EMR and EHR access
- Appointment and scheduling
- Billing
- Inventory management
What solutions can we offer?
Find Out More
Is Mobile App Development Profitable?
The IQVIA Institute for Human Data Science report has found that the consumer digital health app market reached new records in 2020. Over 90,000 healthcare apps were released that year. In general, there are now over 350,000 digital health apps available to consumers in stores.
However, the quality of most of them is poor. The main disadvantages of many applications currently on the market include:
- Fuzzy structure that does not solve a specific problem
- Lack of clinical data
- Poor usability
- Non-observance of the rules of confidentiality and security
As a result, 83% of applications were installed less than 5,000 times, which together represent less than 1% of total downloads. Meanwhile, the Lucky Hundred Leader Apps have been downloaded over 10 million times. This is almost 50% of the total number of downloads.
Nevertheless, various healthcare mobile apps continue to storm the market. Health IT Outcomes predicted that global mHealth revenue would reach $49.12 billion by 2020.
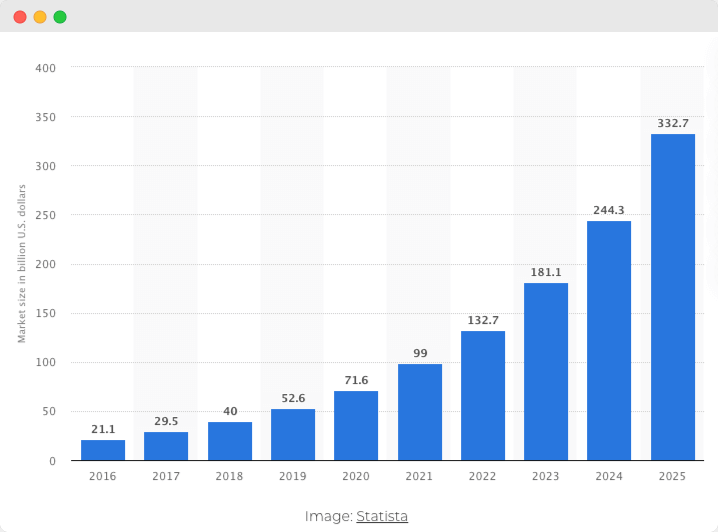
According to a report by ResearchAndMarkets, the global mHealth market size is expected to reach $ 316.8 billion by 2027. Statista expects this figure to rise even higher – to $ 333 billion by 2025. The most optimistic forecast suggests that the global digital health market will increase to over 500 billion U.S. dollars by 2025. During this time, the health information technology segment of the industry should generate the largest revenue share, reaching some 280 billion U.S. dollars already by 2021.
HEALTHCARE CYBERSECURITY: HOW TO PROTECT PATIENT DATA
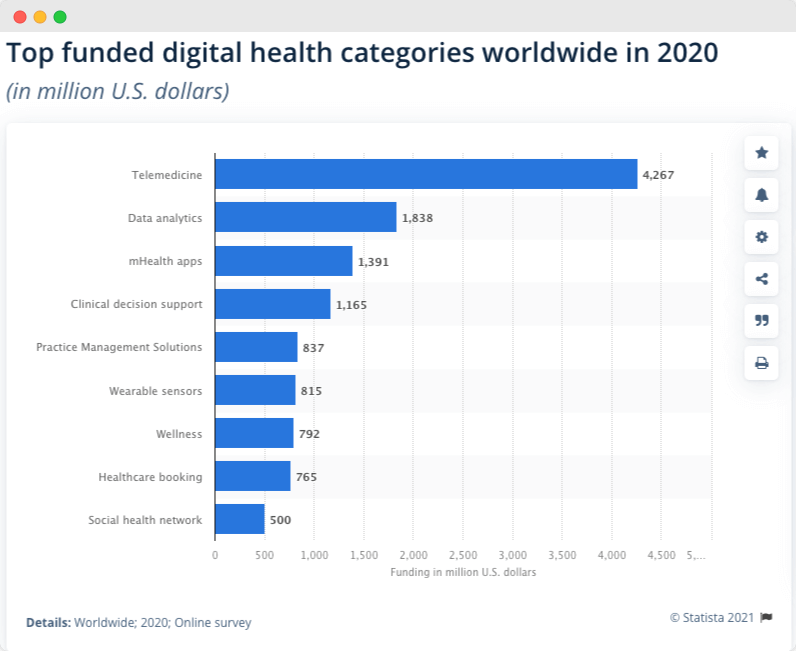
At the same time, back in 2015, Forbes wrote about one million telemedicine patients. By 2018, patient encounters had increased to seven million. This statistic shows the top-funded digital health categories worldwide during 2020. In that year, over 4.2 billion U.S. dollars of funding was provided for telemedicine, making it the most funded category.
Benefits of mHealth apps for business owners
As a health care business owner, you can increase customer loyalty. This will help you with:
- Convenient functionality. Achieved by providing a quality product that will cover all “medical” needs from making an appointment to storing test results, from telemedicine to reminders to buy drugs. This will attract a new audience and increase the loyalty of existing ones.
- Successful marketing. Increase customer engagement with self-reminders. For example, by creating a healthcare app for a specific hospital, you can attract more users with promotions, news, offers, and just being creative.
- Knowledge of the client’s needs. Keeping personal information in your app is the easiest way to collect customer data to improve user experience.
KEY DIFFERENCES IN EHR VS. EMR VS. PHR: WHAT TO CHOOSE FOR YOUR HEALTHCARE ORGANIZATION
Ultimately, the development of a healthcare app helps not only improve a particular hospital’s business processes more efficiently, but also improve the image of both the hospital that ordered the healthcare mobile application development, and the company that developed it.
Do You Want Your Own Medical App?
Contact Us
Healthcare Mobile App Development vs. Covid
The PWC “Medical cost trend: Behind the numbers 2022” report suggests that coronavirus isn’t the only thing affecting the health of Americans. Lack of exercise, poor diet, increased use of psychoactive substances, and smoking…all can lead to poor health in the U.S. population and increased health care costs.
At the same time, App Annie statistics show that there has been a surge in downloads of medical apps in the months of isolation. These country statistics compare downloads in the “peak” local month, with January 2020 considered the benchmark month. The world average is 65%.
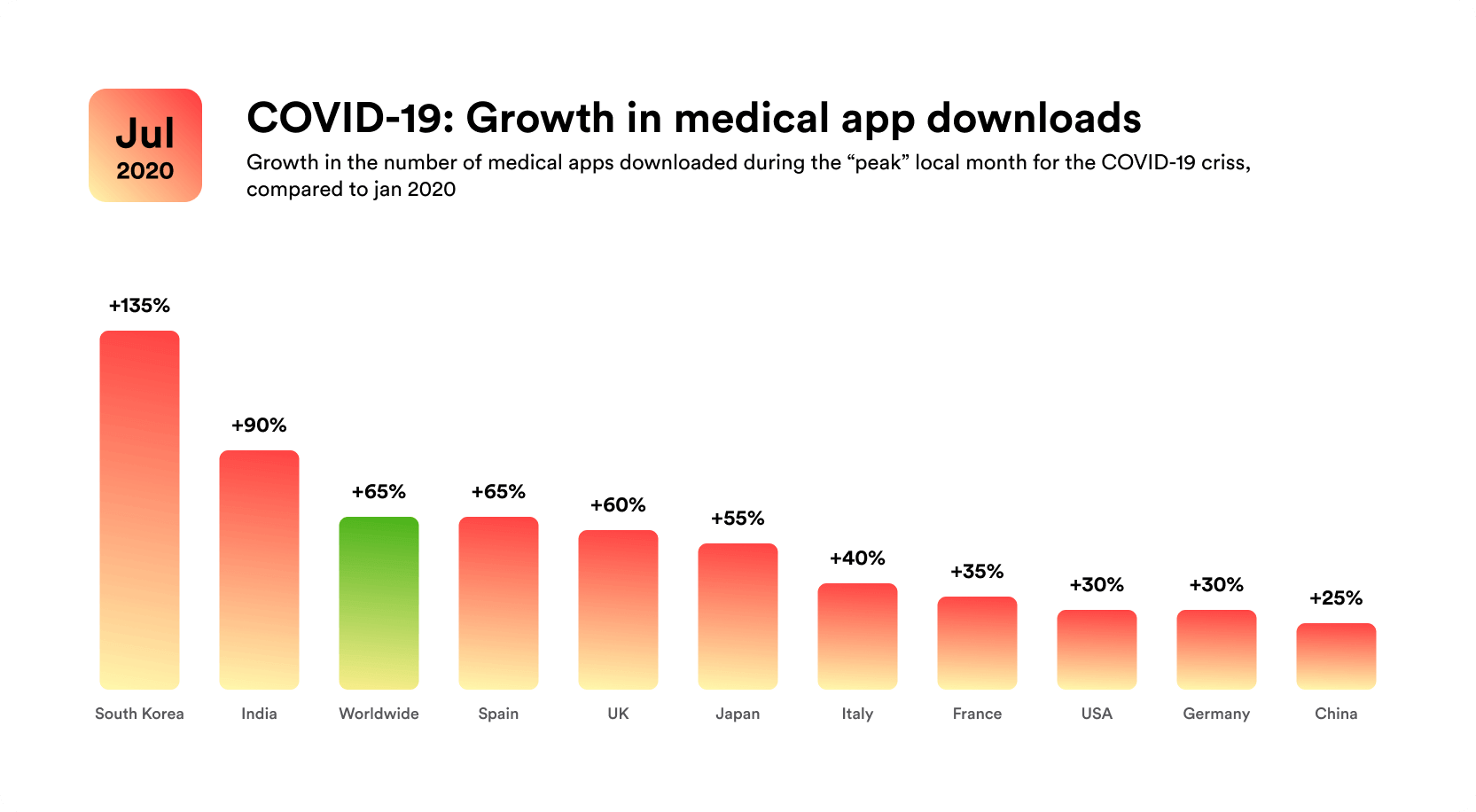
Interestingly, the most significant surge was in South Korea. There, the number of downloads increased by 135%! India’s official tracing app might also be responsible for the 90% upswing we see in that market. We see lower but still significant growth in the European and North American markets as well.
This speaks of both the level of fear felt around the world and desire to be as aware as possible in uncertain times. However, government agencies are using apps as a platform for managing and tracking outbreaks.
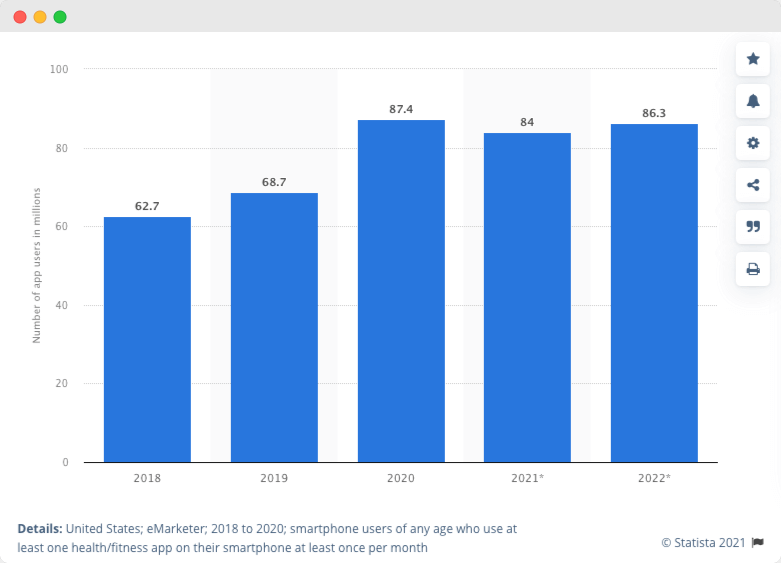
Number of health and fitness app users in the United States from 2018 to 2022 (in millions):
How to Build an Effective Medical Mobile App
About 30% of startups make it to the 10-year mark, with one in five failing in the first year, and the percentage of failed healthcare startups even higher. As mentioned earlier, the most important reason for failure is the inability to identify the target audience, its problems, and how to solve them. In other words, healthcare apps are often not needed at all.
Therefore, in order not to fail, you should clearly define ‘why’ and ‘what’ you are doing. Such simple questions, but the above statistics say that not everyone is asking them.
The process of developing a mobile app can be divided into an almost infinite number of stages. Here are the most basic ones:
- Shaping an idea
- Market Research
- Making an MVP
- Design process
RPA IN HEALTHCARE: A COMPREHENSIVE OVERVIEW, BENEFITS, AND USE CASES

Make sure your mobile healthcare application solves a real problem with enough people. Then, form a clear target audience to further direct all available advertising methods to it. Finally, define a list of features that will only be in your application, and also a list of reasons that prevent you from becoming the best right away.
Conduct detailed research of your competitors to understand their strengths and weaknesses. In this way, you don’t have to waste time adding a new feature your customers are asking for or removing any old parts that nobody needs.
MICROSOFT CLOUD FOR HEALTHCARE: HOW MS CLOUD SOLUTIONS ARE BENEFITING HEALTHCARE ORGANIZATIONS
Healthcare App Development
Before starting work on the healthcare app, we recommend you think about such challenges that you will definitely have to solve within healthcare mobile app development:
- APIs and integrations
- Data encryption
- Multiple devices and channels
- Security and privacy
There is nothing more important to do in the development of healthcare apps, than solving these problems.
Start healthcare mobile app development with MVP. This version should include the basic functionality of any healthcare app. But, of course, it all depends on what type of medical healthcare software you are building. For example, some are exclusively engaged in tracking health indicators, some order medicines for you in pharmacies, and some banally remind you that you need to drink another glass of water. But if you want to create an application that will perform many functions at once, think about the features below.
THE APP SOLUTIONS – CUSTOM HEALTHCARE SOFTWARE DEVELOPMENT COMPANY

Tracking
The doctor and user should be able to independently enter health indicators – height and weight, sugar and cholesterol levels, heart rate and blood pressure, regardless of whether these indicators are measured at home or in the laboratory.
Scheduling
When a patient knows that he has the opportunity to independently book a visit to the doctor in a matter of minutes, he will do it much more willingly than when he needs to call, clarify something and wait for an answer. With this approach, it is easier to miss a visit than to struggle with an appointment. But, of course, we don’t want that, do we?
KEEP A PULSE ON EPIC APP ORCHARD AND HOW IT BENEFITS THE HEALTH SYSTEMS
Notifications and reminders
If the planned visit takes place in a month, or even six months, it is easy to forget about it as well as being reminded to take a pill that you need at a specific time.
Personal account
Allow patients to add their personal information (name, gender, age, etc.) Along with that, permit them to add their health biomarkers and help track them.
Chat and Communication
Allow the doctor to correspond with the patient to enter the conversation results into the necessary documents. To do this, you will need to integrate your healthcare mobile app with the doctor’s software or platform.
WHAT IS ARTIFICIAL INTELLIGENCE IN HEALTHCARE?
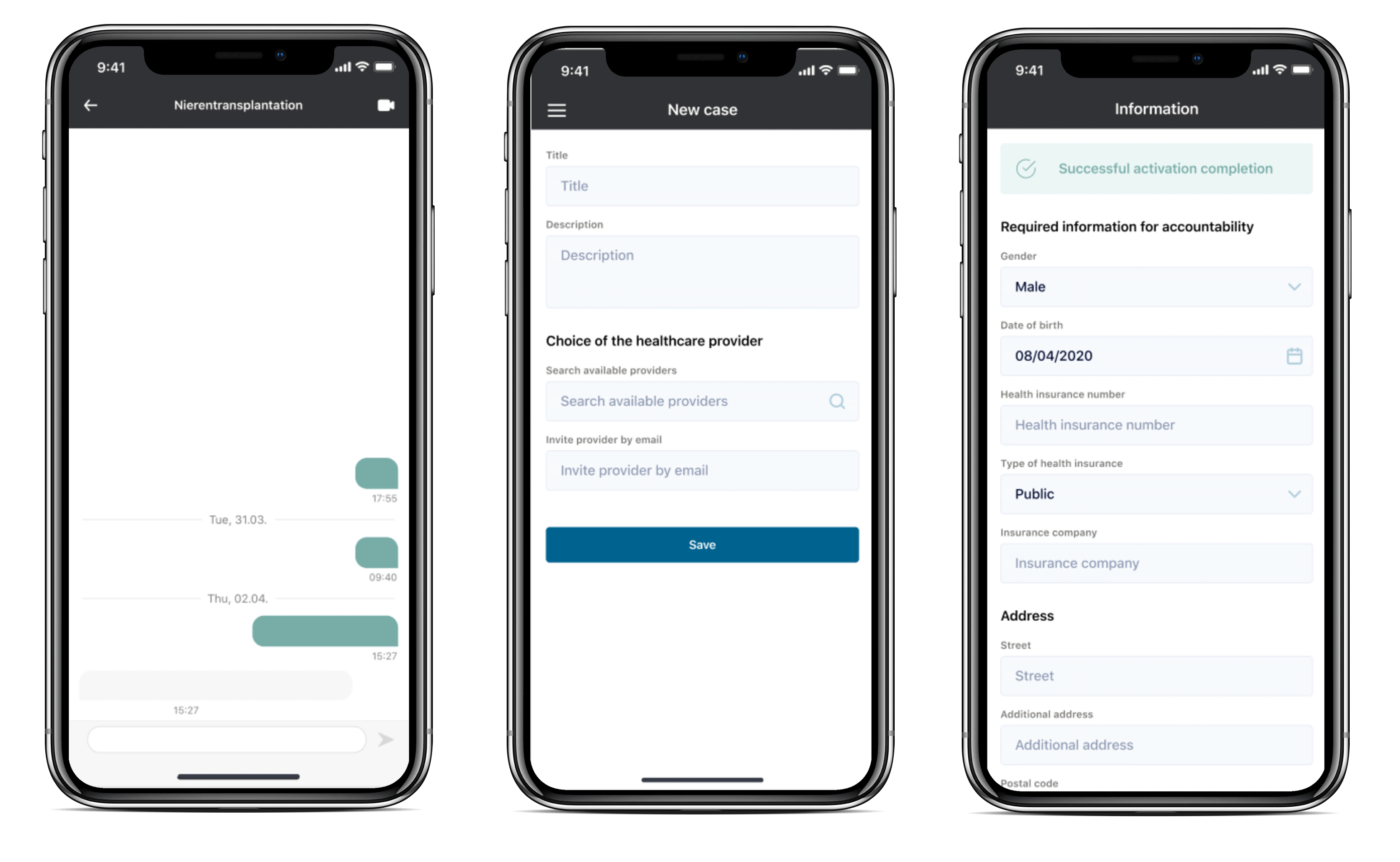
[The APP Solutions layout for a healthcare mobile app]
Telemedicine options
Often correspondence alone is not enough. As mentioned above, video chat with doctors is gaining more and more popularity as it saves time for both the doctor and patient. And, the latter is also not at risk of catching any virus if he doesn’t have to come to the hospital in person.
Geolocation
Allow the patient to find a specialist doctor with good reviews near their location.
File Storage
Hospitals need to create an EHR system to store files securely. As you develop your mobile app, allow users to store their medical data and files.
These can be prescriptions, ECGs, doctors’ recommendations, medical bills.
PREDICTIVE ANALYTICS VS. MACHINE LEARNING: WHAT IS THE DIFFERENCE
Security
A big problem is the distrust of many people in the safety of their data, especially in such an “intimate” sphere. Therefore, place special emphasis on this, do not spare the money spent on security.
Integration with wearables, social integration
Integration with Apple Watch, “garter” to selected social networks.
Search
Create a filter system that can help you find a specific doctor by last name or choose the most suitable one by specialization, location, cost of the visit, etc.
Ratings and reviews
We have long been accustomed to rating the services of taxi drivers and couriers. User feedback about which doctor or hospital will be extremely helpful to future patients and motivate nursing staff to perform even better.
HEALTHCARE APPS DEVELOPMENT: TYPES, EXAMPLES, AND FEATURES
HIPAA Compliant Messaging
The business owner must clearly understand which region they are targeting with their medical app. Where and what kind of correspondence should you pay attention to?
- HIPAA (The Health Insurance Portability and Accountability). The most common rules in the United States were governing confidentiality, integrity, and availability of all electronically protected medical information.
- GDPR (The General Data Protection Regulation). A set of rules adopted and operating in the European Union since 2018. All medical mobile apps must adhere to the provisions on the protection of personal data prescribed in the document. The GDPR applies to both the companies that collect the data and those that process it.
- CCPA (The California Consumer Privacy Act). An analog of the European GDPR. The law includes informing the client about what data is collected, preparing a free report on the collected data at the client’s request, and deleting the collected data at the client’s request.
- PIPEDA (The Personal Information Protection and Electronic Documents Act). A policy designed to safeguard patient privacy in Canada. More often than not a healthcare app that is “confused” with standardization, according to the GDPR, will work with PIPEDA as well since the provisions are very similar.

Payments
You need to decide how you plan to receive income from your medical mobile app. Choose a Monetization Model.
- In-app ads. The healthcare app has no paid options, and it earns by displaying ads
- Freemium. Basic healthcare application options are free, and you need to buy additional exciting features
- Subscription. Users pay only when they use the mobile apps, subscribing for a week, month, year
- Paid. One-time payment for the healthcare app upon purchase
Also, do not forget about those payments that are made between the patient and medical institution. It will be excellent if your healthcare app allows you to pay for doctor visits, order at the pharmacy, and so on.
Only 5.76% of apps are paid, and that number is falling every quarter. As a result, Healthcare apps are usually not monetized and serve as an add-on service in and of themselves.
DATA MINING VS. PREDICTIVE ANALYTICS: KNOW THE DIFFERENCE
What tasks should healthcare mobile apps perform?
The most popular healthcare app functions are:
- Improving health data gathering
- Providing timely care, despite the location
- Minimizing medical mistakes
- Lowering spending for healthcare providers and patients
- Improving communication between physicians and patients
- Increasing customer loyalty and engagement
- Providing time-saving features for medical staff
UI/UX Design in medical mobile app development
When create a medical app design, you need to remember you are making them for a “sensitive” target audience. Remember that your healthcare mobile application may be used by older people who are not good at all these “newfangled things.” Also, users can be people with specific mental and physical disabilities. Accordingly, in this case, you need to focus on an intuitive interface as never before.
Minimize the number of actions the user must take to complete the task. For example, you can group related content to make it available with one click.
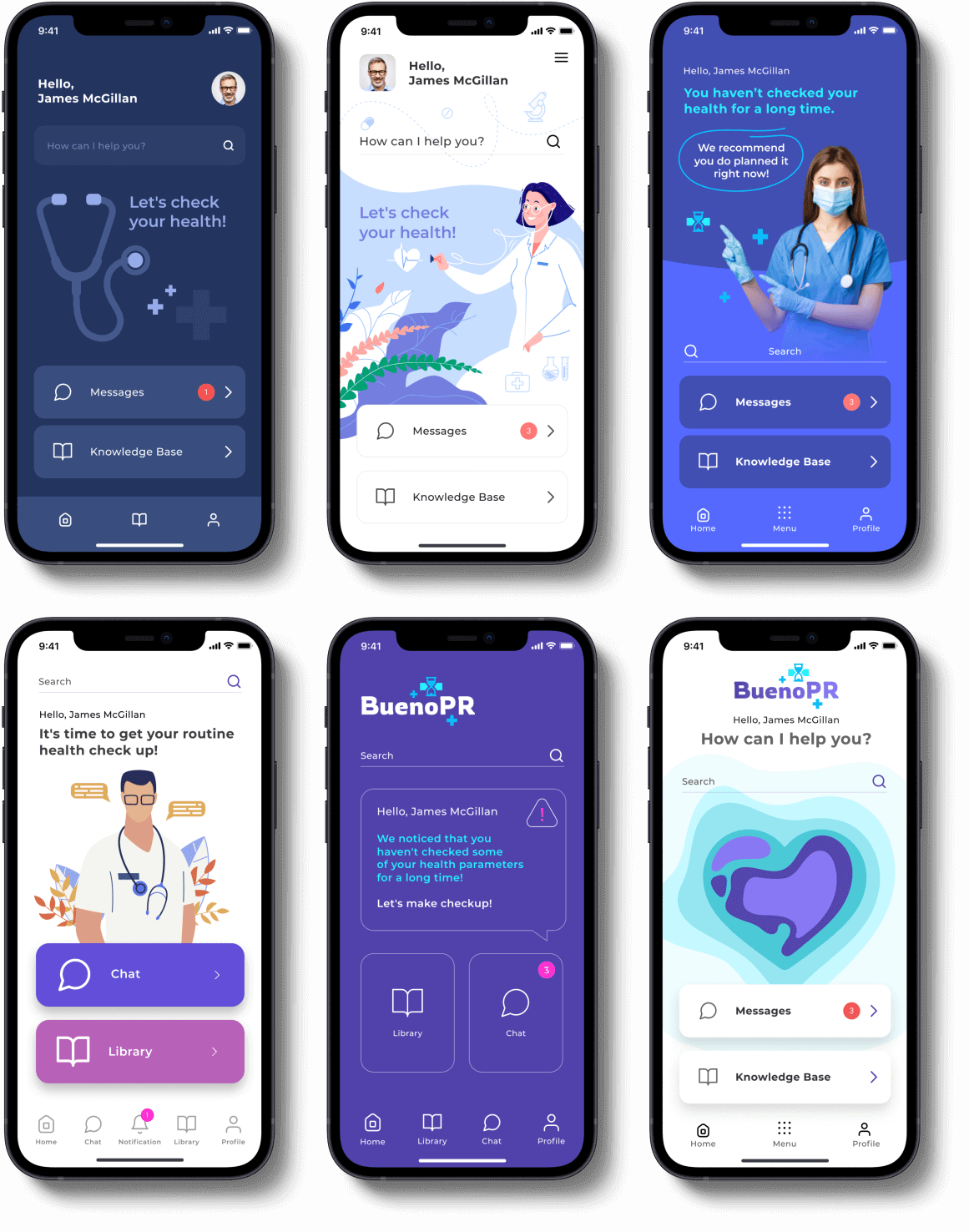
[The APP Solutions layout for a healthcare mobile app]
We recommend using cool colors for the background, warm colors for markers. You shouldn’t use more than three different fonts – choose their sizes following the target audience. The font color should be easy to read and contrast with the background of the healthcare app. Avoid using colored fonts as their visibility is poor. Usually, the best choice is black or dark gray on a light background. It will not be superfluous to accompany the pressing of buttons with characteristic sounds.
And of course, don’t forget about responsive app design!
WHY CREATE A CUSTOM MENTAL HEALTH APP
Trends in mobile medical software development
In whatever year your healthcare app is developed, it should always remain up-to-date. To do this, you need to track trends, the successful implementation of which will allow you to bypass the competition. And most importantly, both doctors and patients benefit from this.
AI
It is difficult to find an area in which AI technologies would be inapplicable. However, it was a medicine that became the flagship of this trend. Moreover, these are not always global tasks, such as how to overcome cancer. As a rule, these are simple administrative tasks that are not noticeable at first glance, but they free up a lot of time for medical staff to plan – optimizing their work.
With the help of the ability to analyze vast amounts of data, artificial intelligence can identify the most critical patients in a group with similar symptoms or, based on practical experience, prescribe appropriate treatment to a new patient. Artificial intelligence can diagnose diseases, and can also recommend medicines. And of course, where would we be without chatbots!

Blockchain
The healthcare blockchain is used to manage electronic health records, conduct clinical and biomedical research, monitor patients remotely, improve insurance and billing procedures, and analyze medical data. In addition, the blockchain ensures that all transactions are conducted confidentially and without third-party intervention, which is HIPAA and GDPR compliant.
The Internet of Things (IoT)
By 2025 there will be a total of 41.6 billion connected IoT devices, which means there will be more connected “things” than people. And this is not the limit. Thus, more and more medical ecosystems will be created, simplifying the interaction between doctor and patient. For example, the doctor will be able to conduct remote examinations of internal organs and progressive diseases. Likewise, the hospital management will monitor and take into account medications and the use of special equipment.
Patient-Generated Health Data (PGHD)
This is information that the patient enters on their own, or with the help of family members, to the healthcare app. At first glance, this is not the best solution since it is not known how honestly, correctly, and objectively the patient will enter data about himself. A doctor would, of course, do this much more accurately. Nevertheless, the practice has shown that this is a working scheme. And again, a win from all sides.
For example, a patient with a chronic disease monitors his indicators, diligently entering them into a mobile healthcare app. A doctor can go there, quickly go over all the details and decide whether to adjust the treatment. This solution significantly reduces the burden on clinicians.
Telemedicine
You may say that this is not a trend. Video communication with a doctor has become a habit for a long time. However, it was in the era of coronavirus that telemedicine became more relevant than ever. Not surprisingly, 42% of adults in the United States say they prefer to have their sessions with doctors online, so they don’t end up in danger. As already mentioned, the most money is now being invested in healthcare mobile app development with this function.
In addition, telemedicine covers the needs of that part of the population that lives far from medical facilities. But this can work not only within one country. As a result, video communication with qualified doctors has become a real salvation for underdeveloped countries. In such conditions, the apparent shortage of doctors in failed states has noticeably improved.
VR/AR
It’s no secret that virtual reality creates the effect of presence. So how does it help in healthcare? There are many areas – from creating conditions for training surgeons to the bland feeling of being in a fitness club. The fantasy of healthcare app developers is unlimited.

The APP Solutions and mobile app development services
Our company has already been developing mobile healthcare apps for several years. Therefore we have something to offer you – we keep up with the trends, develop innovative and original solutions and bring your wishes to fruition. Among the services we provide are:
- Medical Practice Management Software
- Electronic Health Record Software (EHR/EMR/PHR)
- E-Prescribing Software
- Healthcare CRM
- Data Management/Warehousing
- Predictive Analytics Software
- HIPAA/GDPR Compliance
- Medical Devices Integration

[The APP Solutions layout for a healthcare mobile app]
Check out our portfolio and choose your preferred method of cooperation. The APP Solutions team will do everything to make it as fruitful as possible.
Outcomes
Despite the significant number of healthcare apps that flood the market every year, this is far from the limit. All over the world there is a trend towards taking care of one’s health. Covid 19 was the impetus for improving the systematization of patient data in the healthcare sector. Global digitalization has created whole new directions; maybe something new will appear soon that you will come up with and our company can help you implement your idea in healthcare mobile app development!
Any interesting thoughts on your mind?
Contact Us